TFO(tcp fast open)简介
这个是google的几个人提交的一个rfc,是对tcp的一个增强,简而言之就是在3次握手的时候也用来交换数据。这个东西google内部已经在使用了,不过内核的相关patch还没有开源出来,chrome也支持这个了(client的内核必须支持). 要注意,TFO默认是关闭的,因为它有一些特定的适用场景,下面我会介绍到。
这个是google的几个人提交的一个rfc,是对tcp的一个增强,简而言之就是在3次握手的时候也用来交换数据。这个东西google内部已经在使用了,不过内核的相关patch还没有开源出来,chrome也支持这个了(client的内核必须支持). 要注意,TFO默认是关闭的,因为它有一些特定的适用场景,下面我会介绍到。
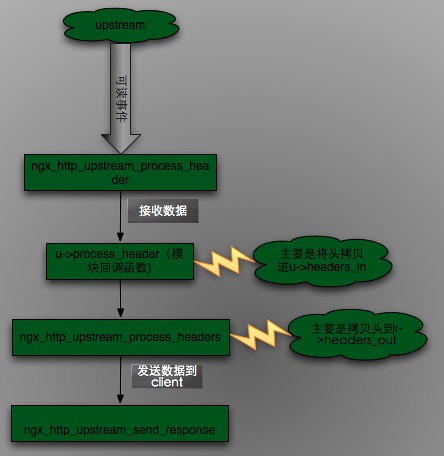
这次主要来分析当upstream发送过来数据之后,nginx是如何来处理。不过这里我忽略了cache部分,以后我会专门来分析nginx的cache部分。
在前面blog我们能得知upstream端的读回调函数是ngx_http_upstream_process_header,因此这次我们就从ngx_http_upstream_process_header的分析开始。
下面是ngx_http_upstream_process_header执行的流程图.
这里就不贴源码了,源码分析的话,网上一大堆,我这里只是简要的描述下epoll的实现和一些关键的代码片段。
相关的文件在 fs/eventpoll.c中,我看的是2.6.38的内核代码.
1 epoll在创建的时候会调用anon_inode_getfd新建一个file instance,也就是epoll可以看成一个文件。因此我们可以看到epoll_create会返回一个fd.
1 |
|
2 epoll所管理的所有的句柄都是放在一个大的结构eventpoll(红黑树)中,而这个结构是保存在file 的private_data域中的(因为epoll本身就是一个文件).这样每次通过epoll fd就可以直接得到eventpoll.
1 |
|
3 每一个加入到epoll监听的句柄(也就是红黑树的一个节点)都是一个epitem.它包含了一个 struct eventpoll *ep,也就是它所属于的eventpoll(epoll实例).
1 |
|
这次主要来看upstream的几个相关的hook函数。
首先要知道,对于upstream,同时有两个连接,一个时client和nginx,一个是nginx和upstream,这个时候就会有两个回调,然后上篇blog中,我们能看到在upstream中,会改变read_event_handler和write_event_handler,不过这里有三个条件,分别是
1 没有使用cache,
2 不忽略client的提前终止
3 不是post_action
1 |
|
在nginx的模块中,分为3种类型,分别是handler,filter和upstream,其中upstream可以看做一种特殊的handler,它主要用来实现和后端另外的服务器(php/jboss等)进行通信,由于在nginx中全部都是使用非阻塞,并且是一个流式的处理,所以upstream的实现很复杂,接下来我会通过几篇blog来详细的分析下nginx中upstream的设计和实现。
upstream顾名思义,真正产生内容的地方在”上游”而不是nginx,也就是说nginx是位于client和后端的upstream之间的桥梁,在这种情况下,一个upstream需要做的事情主要有2个,第一个是当client发送http请求过来之后,需要创建一个到后端upstream的请求。第二个是当后端发送数据过来之后,需要将后端upstream的数据再次发送给client.接下来会看到,我们编写一个upstream模块,最主要也是这两个hook方法。
首先来看如果我们要写一个upstream模块的话,大体的步骤是什么,我们以memcached模块为例子,我们会看到如果我们自己编写upstream模块的话,只需要编写upstream需要的一些hook函数,然后挂载到upstream上就可以了。
这里主要是针对linux下的路由一些基本概念.
1 路由是位于L3(ip层)。
2 路由表(routing table)也叫做Forwarding Information Base(FIB).
3 路由器之间通过路由协议(routing protocols)进行信息的交换.
4 一个路由表包含了一大堆的路由,一个路由就是存储了一些传输数据包到给定地址的必须信息。在linux里面一个路由主要包括了这三个参数,分别是目的网络地址,需要使用的设备以及下一跳网关(next hop gateway)。
在nginx中使用了send_file 并且配合TCP_CORK/TCP_NOPUSH进行操作,我们一般的操作是这样子的,首先调用tcp_cork,阻塞下层的数据发送,然后调用send_file发送数据,最后关闭TCP_CORK/TCP_NOPUSH.而在nginx中不是这样处理的,前面两步都是一样的,最后一步,它巧妙的利用的http的特性,那就是基本都是短连接,也就是处理完当前的request之后,就会关闭当前的连接句柄,而在linux中,如果不是下面两种情况之一,那么关闭tcp句柄,就会发送完发送buf中的数据,才进行tcp的断开操作(具体可以看我以前写的那篇 “linux内核中tcp连接的断开处理”的 blog) :
1 接收buf中还有未读数据。
2 so_linger设置并且超时时间为0.
而如果调用shutdown来关闭写端的话,就是直接发送完写buf中的数据,然后发送fin。
ok,通过上面我们知道每次处理完请求,都会关闭连接(keepalive 会单独处理),而关闭连接就会帮我们将cork拔掉,所以这里就可以节省一个系统调用,从这里能看到nginx对细节的处理到了一个什么程度。
接下来还有一个单独要处理的就是keepalive的连接,由于keepalive是不会关闭当前的连接的,因此这里就必须显式的关闭tcp_cork。
这次主要来看nginx中对keepalive和pipeline的处理,这里概念就不用介绍了。直接来看nginx是如何来做的。
首先来看keepalive的处理。我们知道http 1.1中keepalive是默认的,除非客户端显式的指定connect头为close。下面就是nginx判断是否需要keepalive的代码。
1 |
|
在nginx中request的buffer size我们能够通过两个命令进行设置,分别是large_client_header_buffers和client_header_buffer_size。这两个是有所不同的。
在解析request中,如果已经读取的request line 或者 request header大于lient_header_buffer_size的话,此时就会重新分配一块大的内存,然后将前面未完成解析的部分拷贝到当前的大的buf中,然后再进入解析处理,这部分的buf也就是large_client_header_buffers,也叫做large hader的处理。接下来我会通过代码来详细的分析这个过程。